×
![Modal Image]()
For software teams, the challenge is no longer proving that AI can generate code. It can. The real challenge is using it in a way that preserves architecture, reliability, security, and sound product judgment.
The public narrative focuses on speed and access: GitHub and Microsoft found a 55.8% faster completion time in a controlled coding task, McKinsey reported up to 2x faster completion for some developer tasks, and coverage from Microsoft and Ars Technica has framed vibe coding as a way for more people to build software from natural-language prompts.
At Amplified, we see this through the lens of a software development agency working with startups and product teams to design, build, and scale digital products. Over the past three years, our team has been testing AI tools across client projects and integrating agentic coding practices into real delivery workflows.
In this article, agentic coding means using AI agents to support parts of the development workflow: repository exploration, implementation planning, code changes, command execution, debugging, tests, reviews, and PR preparation.
The old model of AI-assisted coding was simple: the developer asks, the AI answers. It works well for autocomplete, snippets, quick explanations, and isolated tasks, but it rarely understands the full delivery context: product flows, architecture, conventions, testing standards, deployment constraints, and code ownership.
The new model is different: the developer delegates, the AI agent executes.
Agentic coding means using AI not only to generate answers, but to perform parts of the development workflow.
Agentic coding means using AI not only to generate answers, but to perform parts of the development workflow. In practice, this can include:
This changes the developer's role. The developer spends less time on repetitive execution and more time defining the problem, steering the agent, reviewing the output, and validating the result.
From our internal observations, AI agents are already useful for repetitive engineering work, testing support, debugging, SQL queries, package upgrades with breaking changes, research, documentation, and onboarding, but they remain unreliable when tasks are ambiguous, complex, or lack enough context. Mature AI-assisted development is therefore not just about using agents, but about choosing the right mode of interaction for the right type of work.
Modern AI coding environments increasingly separate the workflow into different modes. Our team describes this through three practical categories: Ask Mode, Plan Mode, and Agent Mode.
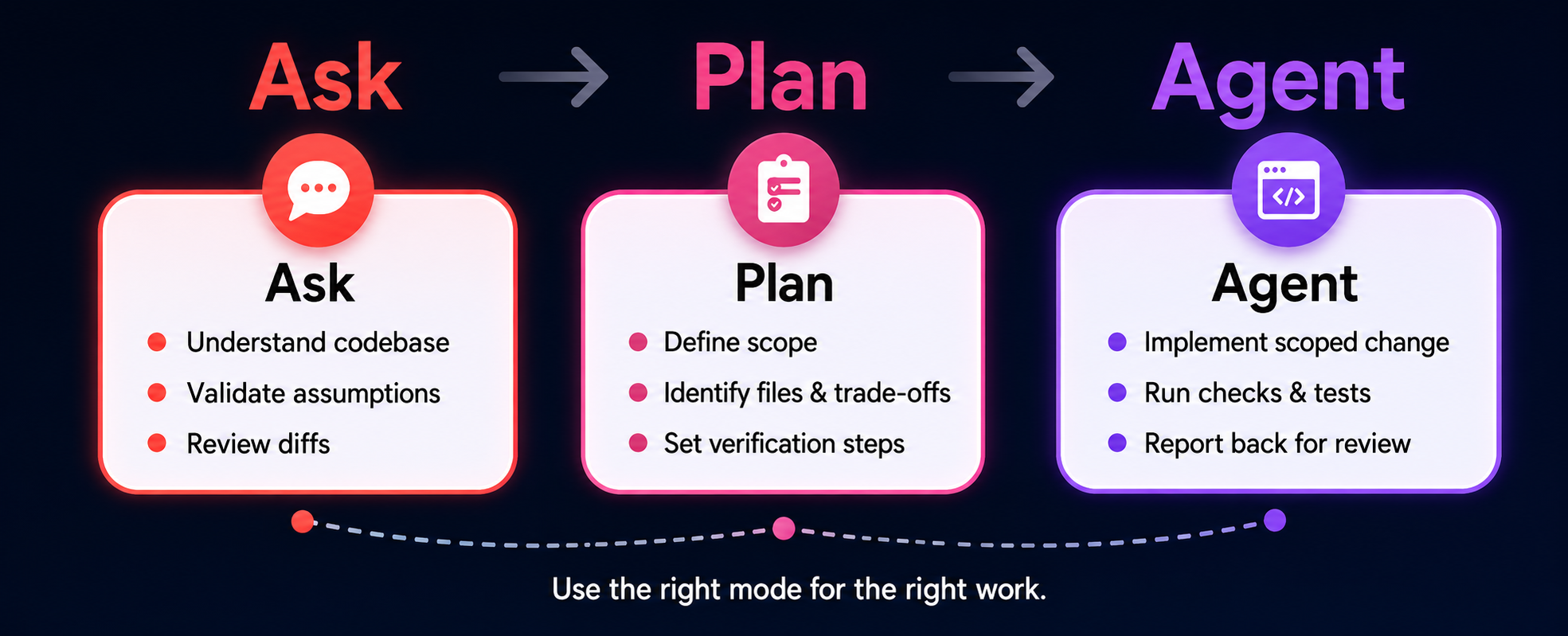
This distinction frames agentic coding as a workflow where teams intentionally decide when the agent should explain, plan, or execute, rather than treating it as a single capability.
Agentic coding works best when the task is clear, limited in scope, and easy to verify. It is especially useful for :
In these cases, the agent can create a useful first draft, but the developer still needs to review and validate the output. The quality of the result depends heavily on the engineer's ability to judge whether it meets the actual goal; when the engineer lacks enough context, plausible-looking output is more likely to be wrong.
The right mode depends on the maturity of the task. Ask Mode is best for repository research, onboarding, understanding existing flows, and reviewing diffs before implementation. Plan Mode works well when the change touches multiple files, affects existing behavior, or needs explicit verification steps. Agent Mode is strongest once the plan is approved and the task is scoped, especially for tests, type coverage, small bug fixes, known patterns, and repetitive migrations.
Effective teams do not default to the most powerful mode. They choose the mode that matches how well the task is understood and how confidently the result can be reviewed.
Agentic coding becomes much riskier when the task is broad, ambiguous, or deeply connected to product and architecture decisions.
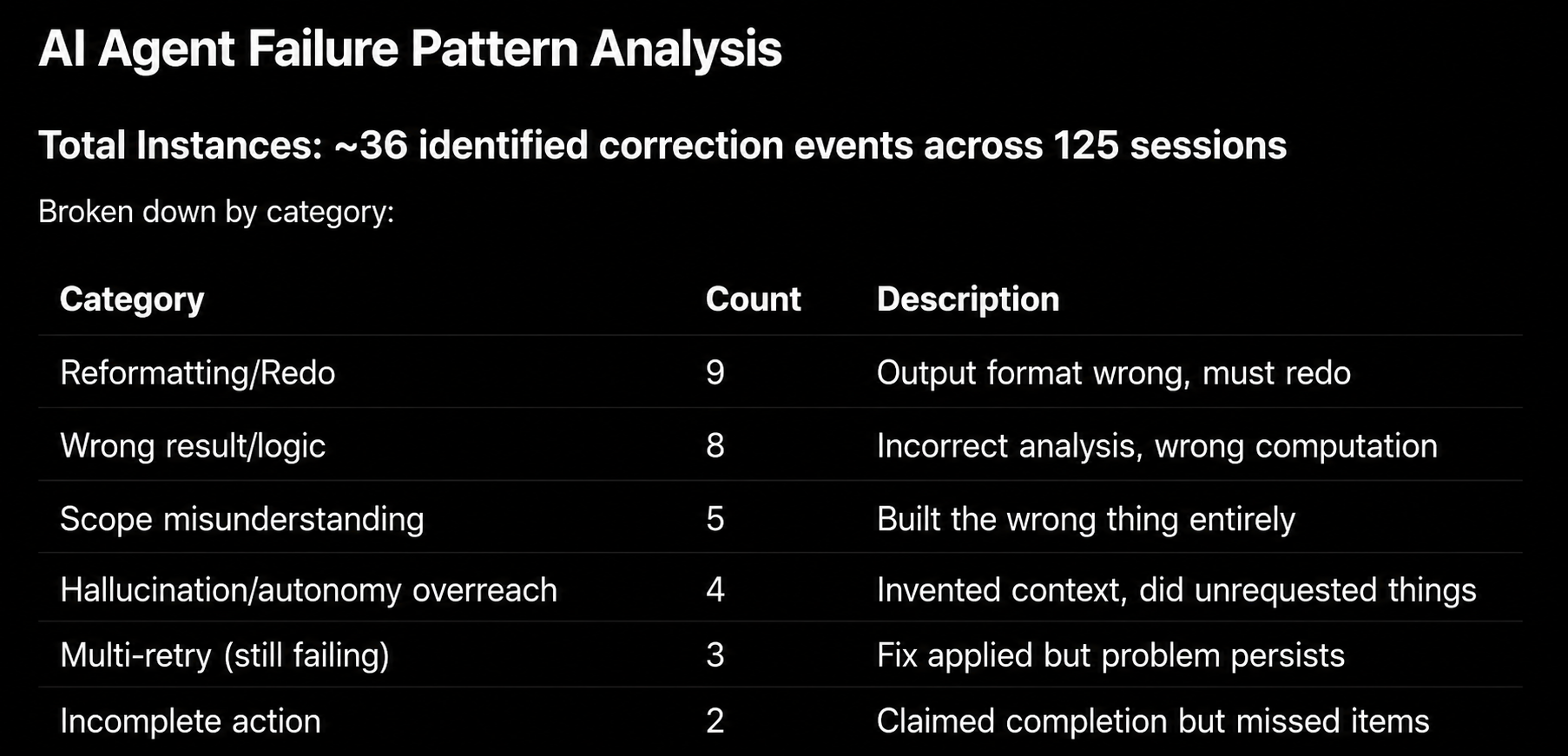
Planning can be hit-or-miss, leading to several critical risks:
Based on our team’s experience, one of the main risks of agentic coding is jumping too quickly into implementation. When the task is ambiguous, Agent Mode can generate a large amount of code before the team has validated whether the direction is correct.
This is especially risky when requirements are vague, trade-offs are unresolved, or side effects are costly. In these cases, Ask Mode and Plan Mode are not overhead; they are risk-control mechanisms.
Agents can also drift: they may misunderstand scope, give confident but inconsistent answers, edit unrelated files, or make choices that were not agreed in the plan. When that happens, it is often better to stop, reset, and re-anchor the task than to keep correcting the same thread.
This connects closely to the team's point that the quality of agentic coding depends heavily on the engineer's ability to review the output. If the human reviewer cannot evaluate the result, then the apparent productivity gain becomes dangerous. The agent may look productive while silently moving the system in the wrong direction.
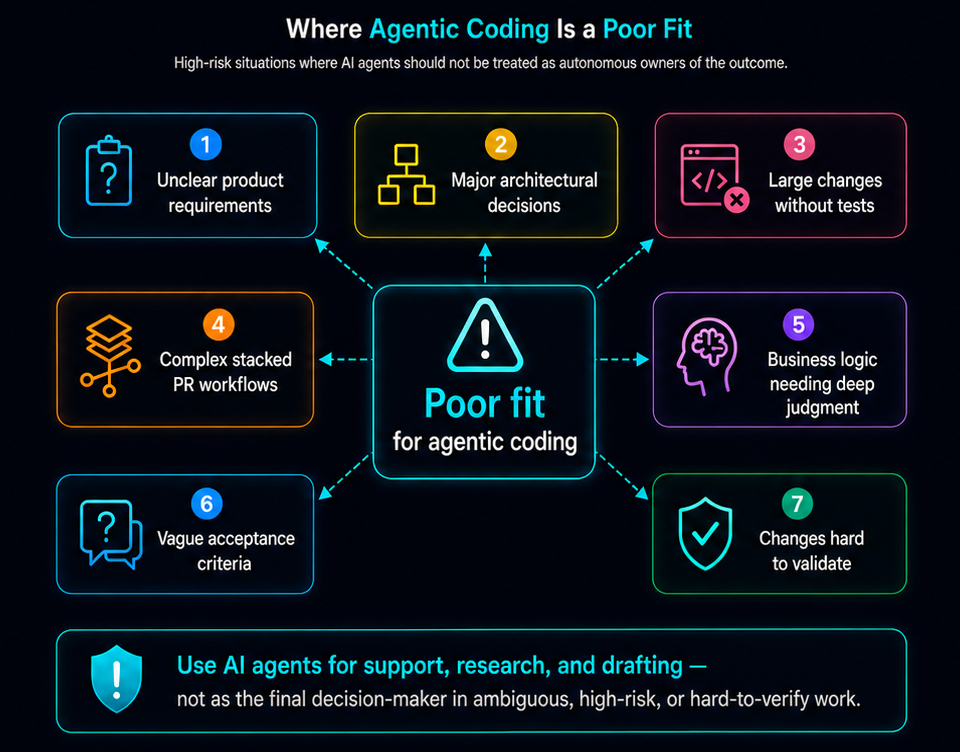
The best results come when AI agents are managed like junior execution partners with strong tooling, not like fully autonomous senior engineers.
A practical agentic workflow follows these steps:
Teams should also define scope clearly by naming what the agent is allowed to touch, while setting explicit limits around high-risk areas such as authentication, billing, permissions, production data, or legacy code.
Finally, rules and guardrails should become part of the codebase rather than remaining one-off prompts. Files such as SKILL.md, CLAUDE.md, CURSOR.md, AGENT.md, project rule folders, and emerging patterns like CONTEXT.md can help agents understand the project, follow team standards, and avoid repeated mistakes. Part 2 will go deeper into the specific prompts, review habits, verification steps, and team-level practices that make this workflow reliable.
Our development engineers draw a clear boundary around human responsibility. AI agents are useful collaborators, but they do not own product or engineering outcomes.
Humans must step in for ambiguity, architecture, judgment-heavy trade-offs, and risk-sensitive areas such as security, privacy, compliance, authentication, payments, permissions, or production data.
They must also evaluate what needs to be experienced, not just reviewed: UX, copy, motion, interaction quality, and overall product feel.
At Amplified, we see agentic coding as a force multiplier for disciplined software teams, not a replacement for engineering discipline. AI agents can speed up implementation, testing, documentation, debugging, research, onboarding, and migration work — but only when their output is guided, reviewed, and validated by humans.
That is why our delivery model is evolving around a clear principle: AI can accelerate execution, but people remain accountable for correctness, maintainability, security, and product fit. Agent-generated work still needs clear requirements, architectural constraints, automated checks, code review, CI/CD, and human ownership.
We explored what agentic coding changes in practice: the developer’s role, the use cases where agents work well, the areas where they struggle, and the discipline needed to keep humans in control.
In the second part, The Best Practices Playbook, we will go deeper into the guardrails, prompts, reviewhabits, verification steps, and team-level practices that help teams use AI agents safely and effectively.