×
![Modal Image]()
AI coding tools are moving beyond autocomplete into full engineering workflows: codebase exploration, implementation drafts, debugging, testing, pull request review, and documentation. But faster code generation does not automatically mean safer product delivery. As Andrej Karpathy notes, teams need to distinguish between casual “vibe coding” and more rigorous agentic engineering: when the marginal cost of producing code drops, the challenge becomes making sure that output translates into real product progress.
At Amplified, our experience points to a clear pattern: AI coding works best when it is embedded in a structured engineering workflow. Agents can reduce repetitive work, support debugging, improve test coverage, and help teams navigate large codebases, but they should not be asked to infer missing requirements, own architecture, or ship unreviewed changes. Our internal analysis made this especially visible: reactive bug fixing and repetitive PR review triage represented 51% of the analyzed sessions, while only 15% were primarily spent on direct feature implementation.
What We Do Not Believe

The best AI coding workflows are collaborative: humans define the intent, agents accelerate execution, and humans validate correctness.
A strong developer-agent workflow usually looks like this:
In The Last Software Engineer, Kent C. Dodds makes a useful distinction: the role of software developers is shifting. In the past, the challenge was aiming at the right feature and building it. Today, AI agents increasingly act like homing arrows that can steer themselves toward implementation. The scarce resource is no longer code production alone, but product engineering: the human judgment required to decide exactly what should be built.
The bottleneck is shifting away from manually writing every line of code and toward defining better tasks, testing outputs, reviewing changes, and understanding how those changes affect the broader system. As AI accelerates implementation, human judgment becomes even more important for validation, quality, and direction.
Why Engineering Discipline Still Matters
Agentic coding does not remove the need for strong engineering discipline. It makes that discipline more important. When AI can generate code quickly, the quality of the surrounding workflow becomes the deciding factor: how clearly the task is defined, how well constraints are documented, how carefully outputs are tested, and how thoroughly changes are reviewed.
Bounded Workflows
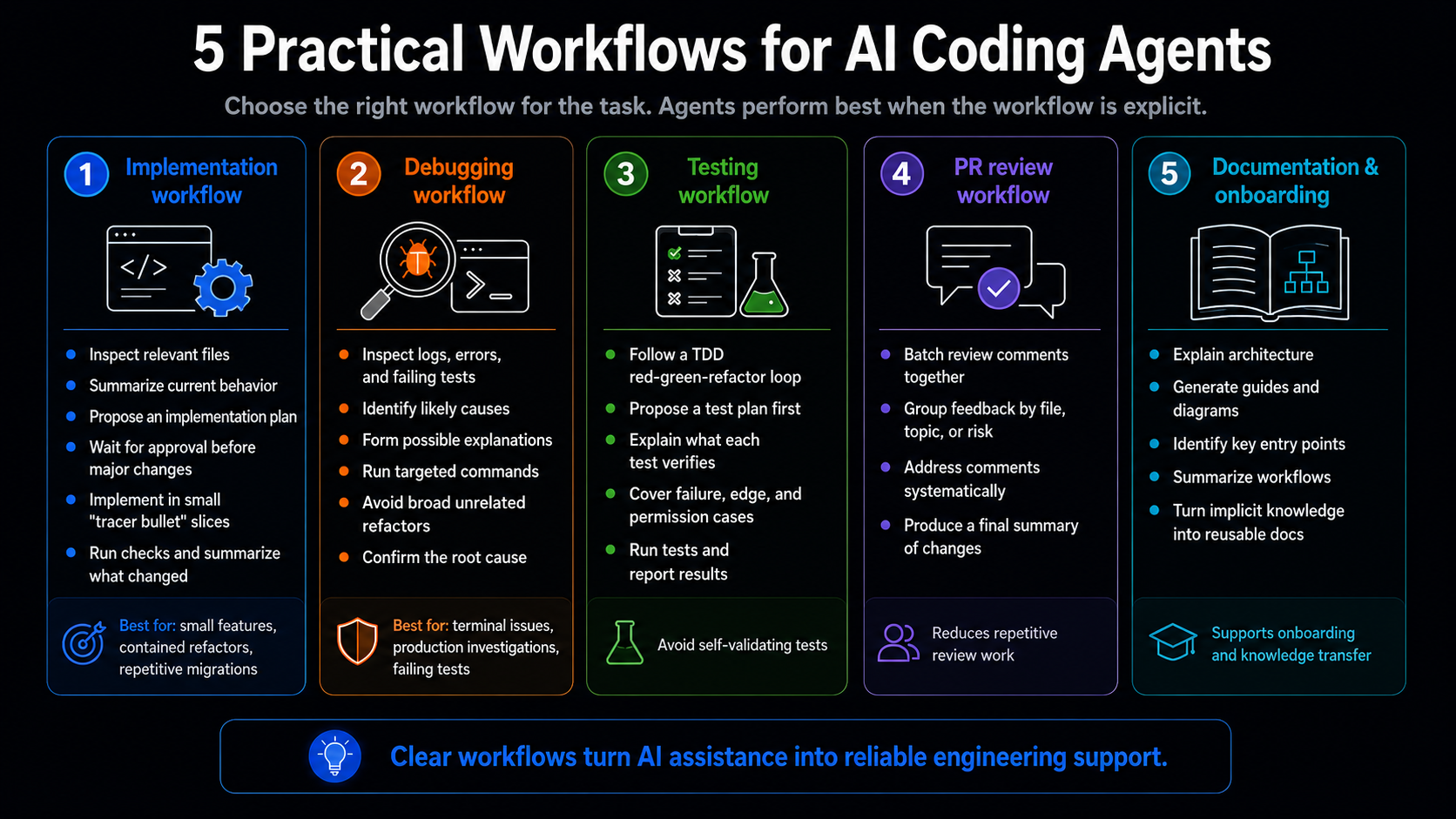
For agentic coding to be useful in real product environments, teams need approved workflows.
A good workflow does not give the agent unlimited autonomy. It defines what the agent can do, when it must stop, and what must be verified before changes move forward.
Good prompts are specific, constrained, and outcome-driven. Instead of asking an agent to “implement this,” developers should define scope, constraints, and validation steps: use the existing service layer, follow known component APIs, propose a plan before coding, run build, lint, and relevant tests, and never create commits or PRs without approval.
Effective prompts reduce guessing by providing exact file paths, line references, API signatures, expected versus actual behavior, security failure modes, feature flag patterns, permission guards, known build errors, and test requirements. Existing code should remain the repository’s source of truth.
Agents work best with clear task boundaries. Broader requests should be split into scoped steps that clarify what to change, what not to change, and what validation is required.
Good agentic tasks include:
Weak tasks include:
Teams should work in tight loops: make one change, run the app or tests, review the diff, and refine. For debugging, include hard evidence — error messages, stack traces, logs, timing data, and reproduction steps — before asking for a conceptual fix, boundary-case analysis, and targeted fixtures.
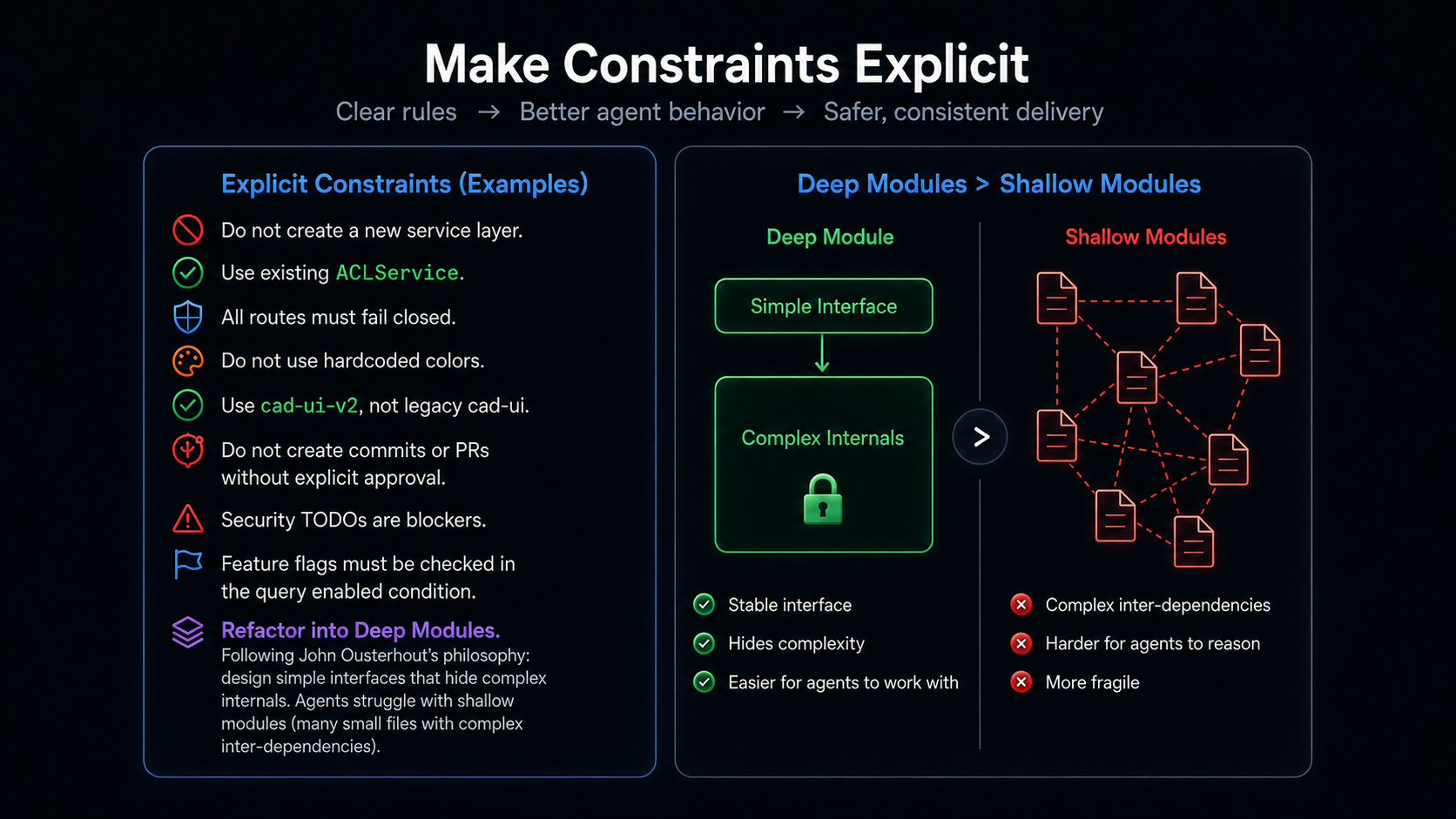
Explicit constraints give AI agents clearer boundaries: what to reuse, what to avoid, and where not to improvise. Inspired by John Ousterhout’s deep module philosophy, the goal is to expose simple, stable interfaces while hiding complex internals, making systems easier for both humans and agents to reason about safely.
Verification and testing should be mandatory parts of the pre-submit workflow, not optional follow-up tasks. Before any commit or PR submission, agents should run a structured verification process covering component API verification, route protection checks, input validation, loading, empty, and error states, permission gates, security TODOs, and build, lint, and test execution.
Testing should be deliberate, not automatic. Agents should not write tests blindly; before generating test files, they should explain what behavior each test verifies, what bug it would catch, what real failure would make it fail, which edge cases are covered, and which tests would be tautological.
This prevents false confidence from AI-generated tests that look useful but do not validate real behavior. The retrospective recommended a pre-submit-checklist skill and a test-strategy validation step to ensure verification catches implementation risks early and testing remains behavior-focused.
Project-level instructions keep agents aligned during implementation by defining task rules, testing expectations, security checks, and approval boundaries.
But putting every rule, guideline, and API detail into one giant system prompt can push the agent into the “Dumb Zone” by overloading its attention. Instead, teams should use Progressive Disclosure: give the LLM only the context it needs, when it needs it, without polluting the context window.
This can be managed through two layers:
To prevent recurring AI mistakes and structural decay, teams must move from passive code review to active, automated governance. Guardrails should become non-negotiable checkpoints in the delivery lifecycle, not just markdown guidelines.
The key principle is Separation of Verification: AI-generated code should be validated by manually designed tests or by a separately prompted LLM that only sees the open specification, not the implementation internals.
Teams should also enforce boundary checks in CI/CD using tools like ArchUnit, SonarQube, or custom AST parsers to block layer leaks, direct SQL bypasses, and unauthorized cross-service calls.
Finally, AI agents should work through SDKs, OpenAPI contracts, and abstract interfaces rather than the full repository. This preserves software health while still enabling agentic engineering velocity.
Turning AI Speed into Reliable Engineering Practice
Agentic coding can make software teams faster, but speed alone is not the goal. At Amplified, we see AI coding agents as accelerators for disciplined engineering work, not as replacements for human judgment.
The key lesson is that AI performs best when it works inside clear boundaries: well-scoped tasks, explicit constraints, strong prompts, reusable instructions, testing, CI/CD checks, and careful human review. Agent-generated code should be treated as a draft that must be validated for correctness, maintainability, security, and product fit.
As AI accelerates implementation, engineering discipline becomes even more important. The teams that benefit most will be those that stay in control of requirements, architecture, verification, and delivery quality.
In Part III , What We Are Learning About Making AI Coding More Consistent , we will explore whatmakes AI-assisted engineering more predictable, reliable, and reusable across real projects and delivery workflows.


