×
![Modal Image]()
Most engineering teams are already experimenting with AI coding tools across implementation, debugging, research, PR review, documentation, migrations, and DevOps exploration. But adoption alone does not create consistency. AI coding becomes valuable at the team level when assisted work is reliable, reviewable, and aligned with how the team actually builds software, through shared habits, reusable workflows, clear review practices, and better context for the agent.
At Amplified, we are not claiming to have solved this across every project; we are learning from real usage: where AI agents help, where they fail, what needs human supervision, and which practices can make AI-assisted development more consistent over time.
The first phase of AI adoption is usually individual. Developers try different tools, from Cursor to Claude, and apply them to different parts of their work: backend development, UI, research, or documentation. Prompting styles also vary: some developers write detailed prompts, while others give minimal instructions. Project-level rules differ as well: some teams define strong guidelines, while others have almost none. This is normal. But when AI usage remains highly individual, teams can end up with inconsistent outcomes.
Individual productivity is useful, but inconsistent AI usage can create inconsistent engineering outcomes. Giving a single developer access to a fleet of agents can create the illusion of peak productivity: more code, more parallel exploration, and faster movement. This is essentially the AI-era equivalent of The Mythical Man-Month. As Fred Brooks argued, adding more capacity to software work does not automatically make delivery faster or better, because software development depends on coordination, communication, and shared understanding.
Without shared alignment, parallel agents can amplify merge conflicts, duplicated decisions, technical debt, and review burden. But the answer is not to make every developer work the same way. The goal is consistency where it matters: context, constraints, testing, review, ownership, and approval boundaries.
AI agents are already useful across the engineering workflow: implementation drafts, debugging, documentation scanning, technical discovery, test-plan generation, architecture exploration, repetitive automation, and PR review. They are also moving into operational work such as CI failures, deployment scripts, cloud configuration, staging environments, observability, incident debugging, dependency audits, release preparation, backlog refinement, and operational documentation.
That broader usage changes the risk profile. A bad frontend refactor may break a page, while a bad infrastructure change can take down production, leak data, or quietly increase cloud spend for months. As agents move closer to planning, operations, and coordination work, teams need clearer workflows around context, review, ownership, approval boundaries, and human oversight. A UI cleanup, backend refactor, DevOps investigation, migration, and PR review are different risk classes, so they should not all use the same AI workflow.

As teams adopt AI agents in engineering workflows, consistency depends less on perfect one-off prompts and more on shared operating rules that are easy to find, maintain, and apply.
Files like AGENTS.md, PRODUCT.md, DESIGN.md, and task-specific skills should not remain static documentation. They should be treated as part of the engineering system. Repo-level rules define the baseline operating contract: service boundaries, verification commands, package manager usage, generated files, and actions that require human approval. Product and design context should live in dedicated files, while specialized skills should cover repeatable workflows such as testing, diagnosis, design-system usage, migrations, or API lookup.
The important shift is maintenance. When a team repeatedly corrects an agent with the same instruction — “use this component,” “do not bypass this service,” “check this generated client first,” or “never run this command without approval” — that correction should become a durable rule, checklist, or skill. Over time, this turns individual prompting lessons into shared team infrastructure.
A useful split is simple: keep repo-wide behavior in AGENTS.md, product context in PRODUCT.md, design standards in DESIGN.md, and stack-specific execution guidance in skills. This keeps baseline rules clear while allowing teams to load specific context only when a task requires it.
Skills are most useful when they encode repeatable workflows, not generic advice. Matt Pocock’s .claude directory is a useful example: /tdd enforces red-green-refactor, while /diagnose enforces reproduce, hypothesize, instrument, and fix. The same pattern applies to product engineering, testing, design-system usage, migrations, API lookup, deployment workflows, and architecture checks.
In Amplified audits, agents often hallucinated UI component props, causing broken builds. A /cad-ui-v2-component-lookup skill fixed this by forcing the agent to inspect actual component exports before writing JSX. That is the core value of skills: they turn repeated corrections into reusable execution paths.
For example, a team may use skills to provide specific context around:
Strong skills are narrow, operational, and maintained close to the codebase. They should evolve when components, generated clients, routing conventions, CI commands, or approval flows change. Otherwise, they can become stale and misleading.
The broader lesson is that AI performance is not only a model problem. It is also a context and harness problem. Skills give teams a practical way to shape that harness without overloading every task with the same global instructions.
Token price is easy to compare. Engineering cost is not. For coding agents, the better metric is cost per accepted change: model cost, agent runtime, engineer review time, failed-attempt cleanup, CI cost, and rollback risk.
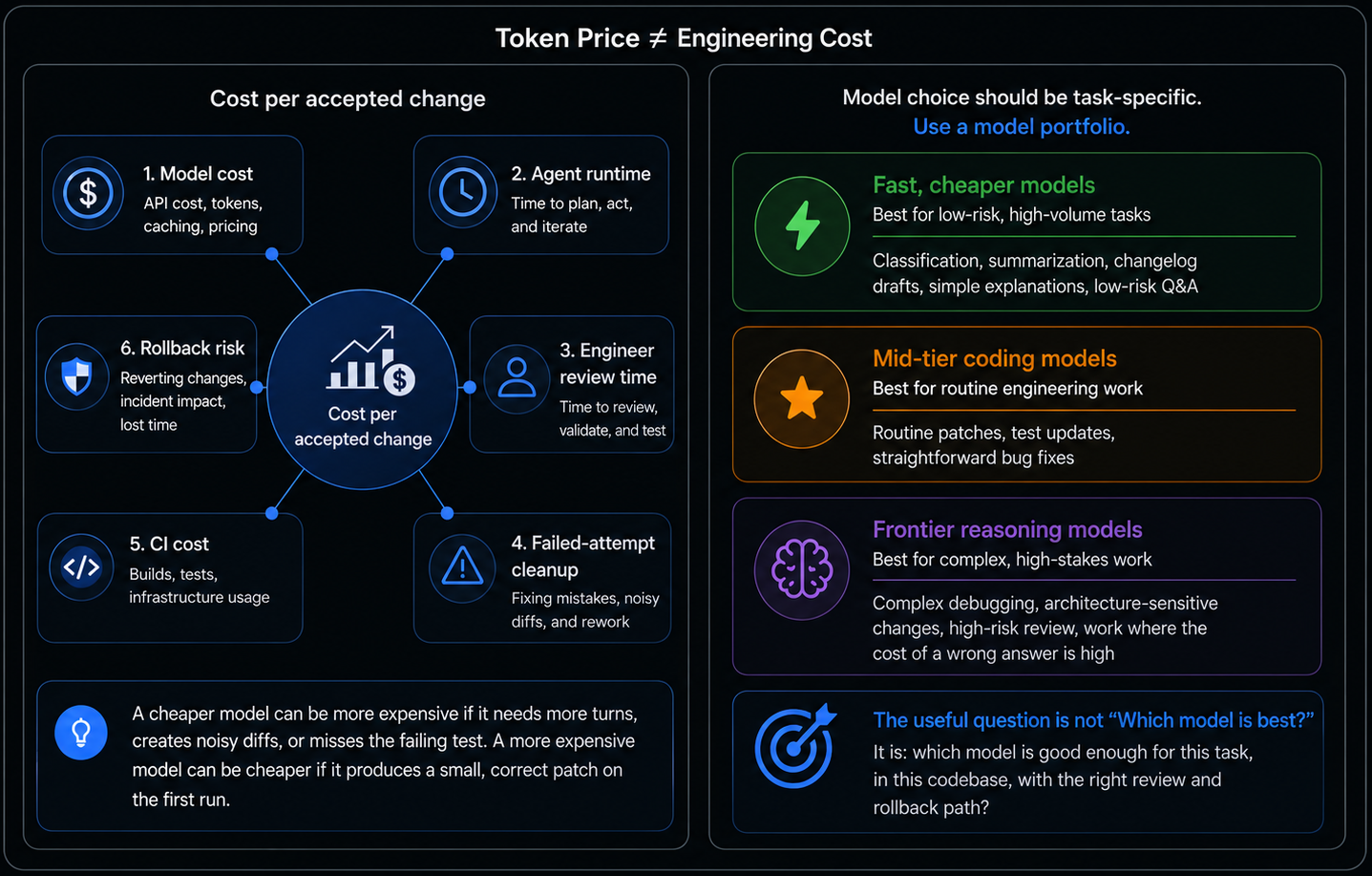
A cheap model can still be expensive if it needs many turns, creates noisy diffs, or misses the failing test. A more expensive model can be cheaper if it produces a small, correct patch on the first run.
Model choice should be task-specific. Different models may perform better on UI exploration, backend reasoning, refactoring, debugging, DevOps work, or large-codebase navigation. This aligns with Andrej Karpathy’s idea of jagged intelligence: models have sharp strengths in some domains and weaknesses in others.
In practice, teams should use a model portfolio. Fast, cheaper models can handle low-risk tasks. Mid-tier coding models can handle routine patches and test updates. Frontier reasoning models should be reserved for complex debugging, architecture-sensitive changes, and high-risk review.
External benchmarks can help shortlist models, but they should not decide deployment on their own. Artificial Analysis is useful here because its LLM Leaderboard tracks intelligence, price, output speed, latency, and context window, while its Coding Agent Index measures software engineering tasks such as repository Q&A, patch generation, and terminal use. Teams still need repo-specific evaluation, review paths, and rollback strategy.
AI agents perform better when a project already has clear architectural patterns. If the project structure is clean, the codebase is consistent, and core components or services follow good conventions, the agent has something reliable to imitate. Because agents infer patterns from surrounding code, they can either reinforce inconsistency or accelerate good engineering practice.
This is especially important in early project stages. Teams should first establish the foundation manually: project structure, core components, naming conventions, service boundaries, utility patterns, testing patterns, design-system usage, and API conventions. As John Ousterhout’s distinction suggests, agents struggle with shallow modules: many tiny files with tangled interdependencies and unclear test boundaries. They work better with deep modules that expose simple interfaces while hiding complex internal logic. AI can accelerate a good pattern, but it can also amplify a weak one, so strong engineering foundations still matter.
Migrations are one of the areas where AI agents can be especially useful because they are often repetitive, bounded, and full of small decisions that need to be applied consistently. A framework upgrade, API rewrite, database refactor, architecture change, library migration, package upgrade, web-to-mobile translation, or multi-file usage update usually contains two kinds of work: judgment work and execution work. Engineers still need to do their own judgment work: target design, rollout strategy, customer risk, compatibility, non-goals, and what must not change. Agents are more useful for execution work: finding call sites, rewriting similar code across many files, generating adapters, updating tests, and chasing edge cases.
The right way to use an agent in a migration is not “migrate us to the new stack.” A better starting point is a short migration brief that describes the current state, target state, non-goals, compatibility requirements, risk areas, verification plan, and rollout plan. Then ask the agent for inventory usage before editing: direct imports, wrappers, runtime configuration, tests, fixtures, CI scripts, generated code, documentation, deprecated paths, and public contracts. The first deliverable should be a reviewable map: group findings by migration approach and classify each item as a mechanical replacement, adapter work, product decision, data migration, release sequencing issue, or dead-code candidate.
Once the inventory exists, the agent can inspect the existing pattern, understand the destination pattern, and apply repetitive transformations across the codebase. This works well for framework migrations, where agents can update imports, convert file conventions, rewrite simple APIs, move configuration, and fix tests. Engineers still need to supervise behavior-sensitive areas: routing, caching, rendering modes, middleware order, form semantics, environment loading, build-time versus runtime execution, platform-specific behavior, edge cases, performance constraints, and UX expectations. The best use of AI in migrations is not “do the whole migration for us,” but “help us understand the existing behavior, apply the repetitive transformation, and produce a reviewable first draft.”
DevOps and infrastructure work require stricter boundaries because agents can move from analysis into actions that affect real systems. A safe starting point is CI: agents can inspect failing logs, identify the first meaningful error, compare against previous passing runs, summarize likely causes, and propose targeted fixes.
For infrastructure, the agent should stay close to the checklist, not the button. It can draft Terraform plans, explain cloud CLI commands, compare staging and production configuration, prepare rollback notes, or identify permission risks. But mutating actions — applying infrastructure changes, modifying production permissions, running destructive SQL, deploying to production, or changing secrets — should require explicit human approval.
This distinction keeps AI useful in operational work without giving it unchecked control over systems where mistakes can affect availability, security, data integrity, or cloud costs.
Consistency does not come from trusting the agent more. It comes from verifying the agent better. AI output should remain reviewable, testable, and explainable.
This means teams need consistent expectations around:
In practice, consistency comes from making agent-generated work easier to review, test, and explain. Teams can support this through small operational norms: smaller PRs, clear notes on which parts were AI-assisted, explicit checks for generated tests, linting, type checks, build checks, security review, permission review, and manual QA where appropriate.
Validation should also match the risk of the change. Low-risk documentation updates, UI cleanup, or mechanical refactors can move faster, while changes involving authentication, permissions, billing, production data, infrastructure, deployments, or customer-facing behavior need stronger review and explicit approval. For debugging and operational workflows, agent output should separate evidence from inference: what the system shows, what the agent suspects, what still needs confirmation, and what the next safest step is.
One of the most effective ways to improve AI adoption is to eliminate repeated failure patterns early. To quantify the cost of failing to do this, consider the "85% Trap”.
In a recent Amplified audit of a 78-session feature build, we found that only 15% of agent sessions contributed directly to implementing the feature itself. The other 85% was consumed by downstream recovery work: bug remediation, repetitive validation cycles, pull request churn, and rework caused by inconsistent assumptions between sessions.
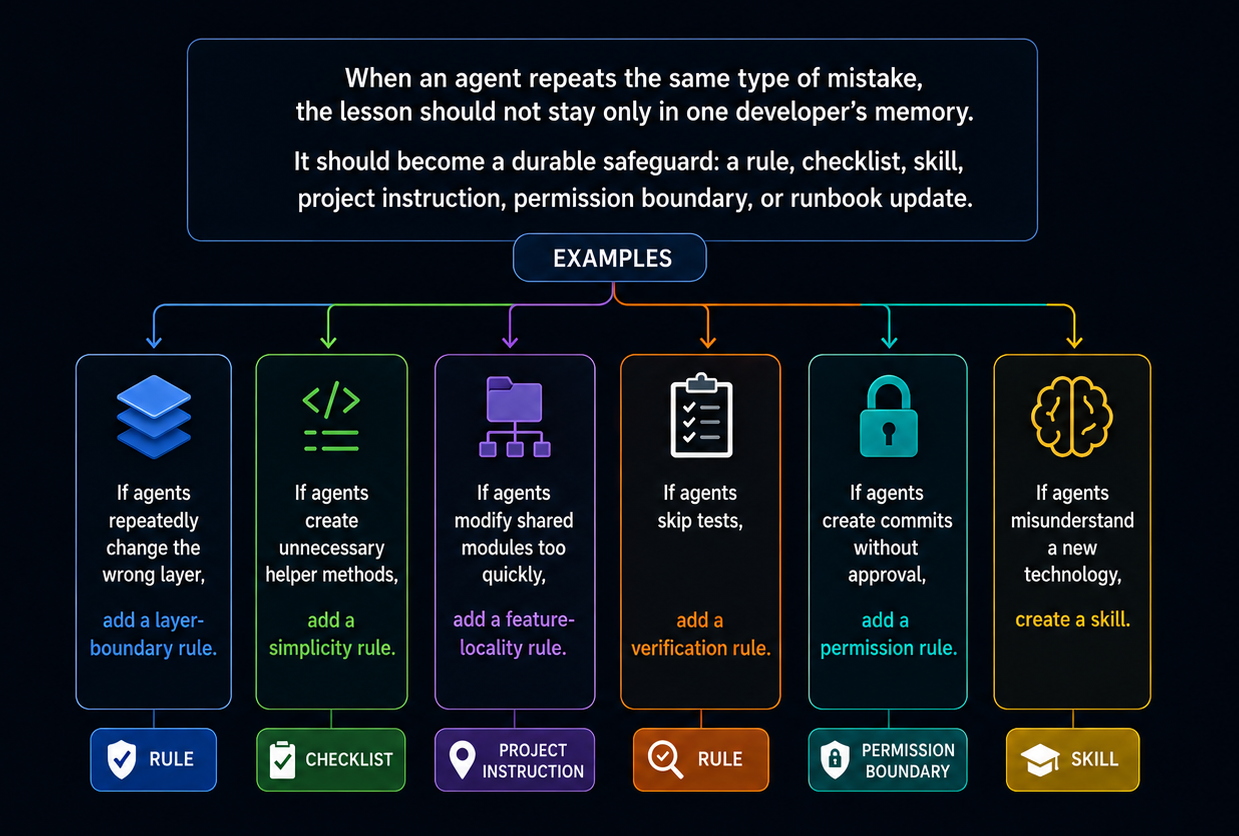
The same principle applies to DevOps automation. If an agent repeatedly proposes unsafe commands, misses rollback implications, comments too noisily on PRs, or confuses staging and production permissions, that learning should become a durable safeguard: a rule, checklist, skill, project instruction, permission boundary, or runbook update.
This is why skills work best when they live close to the codebase and evolve with it. If a routing pattern changes, the skill should change. If a generated client moves, the skill should move. If a verification command becomes stale, the skill becomes actively harmful. Skills should be treated as part of the engineering system, not as onboarding copy.
The goal is to convert corrections into reusable guidance. When someone tells an agent, “not like that, in this repo we do it this way,” that is skill material. Capture the correction, connect it to the relevant files or commands, and define when it should apply.
Over time, this creates a feedback loop: teams use AI in real work, notice repeated failures, identify the root cause, convert the lesson into a rule or skill, and reduce the need for repeated correction. That is how teams move from individual AI usage toward shared AI-assisted engineering practice.
A practical next step for engineering teams is to standardize the operational parts of AI-assisted development that affect quality, safety, and maintainability.
As AI usage scales, inconsistency becomes expensive. Different prompting styles, review expectations, tool choices, and approval habits can create fragmented workflows where AI-generated changes are harder to review, reason about, and maintain.
The goal is not to eliminate experimentation or force identical workflows. Teams still need room to try new tools, models, and prompting approaches, but experimentation works better on top of a stable operational baseline.
That baseline often includes shared expectations around:
The most useful standardization is not about prompts. It is about the engineering process: review, testing, security boundaries, ownership rules, approvals, operational safeguards, and lightweight risk tiers.
Low-risk UI cleanup or documentation updates can move faster, while infrastructure changes, permission modifications, deployment configuration changes, or production-impacting actions require additional review and approval.
The goal is not uniformity. It is to make AI-assisted development more predictable at the team level, not just productive at the individual level.
For clients, AI adoption can feel confusing in a noisy market where some teams overpromise and others avoid it because of concerns around quality, technical debt, or security. The better question is not “Do you use AI?” but “How do you use AI safely, consistently, and responsibly?”
At Amplified, we see AI coding as a practical productivity lever when it is supported by strong engineering process: clear rules, human review, testing, risk controls, defined approval boundaries, and a commitment to keeping code maintainable after delivery. The real value is not isolated productivity gains, but turning individual AI usage into shared engineering practices that teams can trust and improve over time.
That is why consistency is the next frontier of agentic coding. AI agents can help with implementation, research, debugging, documentation, migrations, PR review, and DevOps exploration, but experienced engineers still set the standards for quality, safety, and maintainability. The goal is not to replace engineers, but to give disciplined teams more leverage.


